
8. Mastering Machine Learning: Converting Categories to Binary Brilliance with Python -- Part 2


Hey there, let's pick up where we left off and dive into the cool world of "Label Encoding" today! 😊
Label encoding is a neat trick in the world of machine learning. It's like turning words into numbers. Imagine you have colors like "Red," "Blue," and "Green." Instead of words, we want numbers for our computer to understand.
So, we play a game of assigning numbers:
Red becomes 0
Blue becomes 1
Green becomes 2
Now, our "Color" column speaks numbers: 0 for Red, 1 for Blue, and 2 for Green. Easy, right? 🎨
But why do we do this? Well, it's handy when things have a natural order, like "low," "medium," and "high." We can give them numbers too: 0, 1, and 2.
Remember one-hot encoding? We use that when order doesn't matter. But for things like "Yes" as 1 and "No" as 0, label encoding is perfect!
Now, let's check out our dataset again: 🕵️♂️
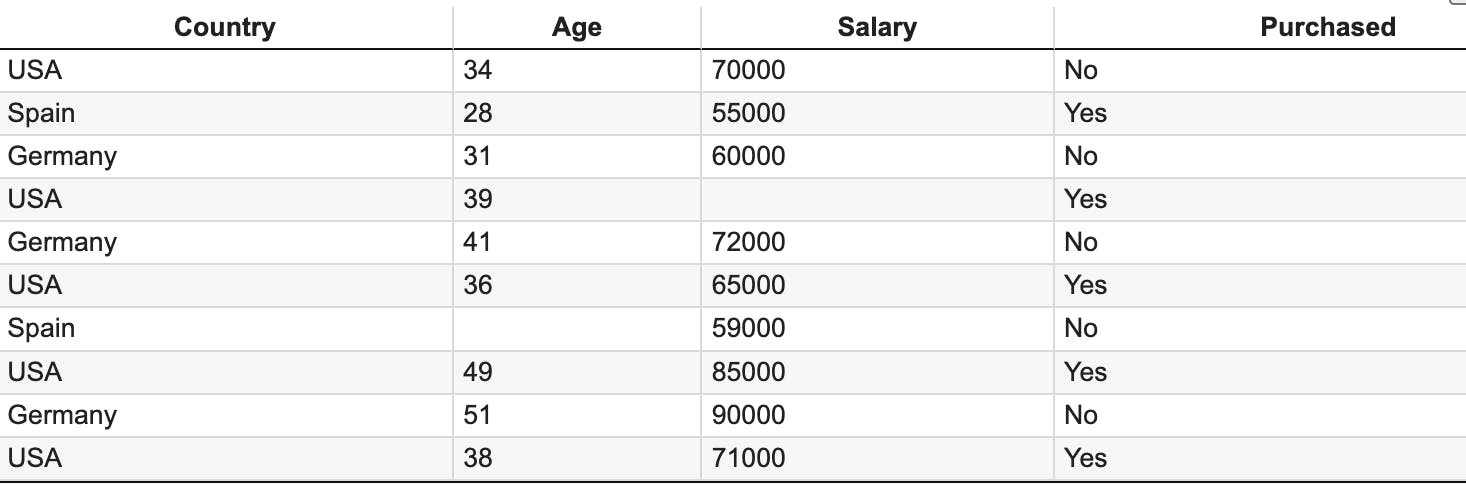
If you notices the "Purchased" column seems like the perfect candidate for applying "Label Encoding."
Now, it's time to roll up our sleeves and dive into some coding to make it happen! 🛠️ Let's go!
from sklearn.preprocessing import LabelEncoder
label_encoding = LabelEncoder()
y_dependent = label_encoding.fit_transform(y_dependent)
Now let's break down each line of code:
from sklearn.preprocessing import LabelEncoder: This line imports theLabelEncoderclass from thesklearn.preprocessingmodule. As we already understood in previous articles too Scikit-learn (sklearn) is a widely used machine learning library in Python, and thepreprocessingmodule within it provides various tools for data preprocessing tasks.label_encoding = LabelEncoder(): This line creates an instance of theLabelEncoderclass and assigns it to the variablelabel_encoding.LabelEncoderis a utility class in scikit-learn used for encoding categorical labels into numerical values. This is often necessary in machine learning tasks since many algorithms require numerical input.y_dependent = label_encoding.fit_transform(y_dependent): This line applies the label encoding transformation to the variabley_dependentwhere we already stored last column of our dataset which having values YES or NO. Here's what happens step by step:label_encoding.fit_transform(y_dependent): This methodfit_transformfits the encoder to the data (y_dependent) and transforms it simultaneously. During the fitting process,LabelEncoderlearns the unique categories present in the data and assigns a unique integer value to each category which is 0 for No and 1 for Yes. Then, it transforms the original categorical labels into these encoded numerical values.The transformed data is then assigned back to the variable
y_dependent. So,y_dependentnow contains the numerical representations of the original categorical labels with values 0 and 1 only.
To summarize, this block of code imports the LabelEncoder class from scikit-learn, creates an instance of it, and then applies label encoding to the y_dependent variable, converting categorical labels into numerical representations. This preprocessing step is often necessary before feeding categorical data into machine learning algorithms.
Now, let's run this block of code in our current session. Let's give it a go! 🚀💻

Yayyyy, we did it! 🎉 Our entire dataset is now transformed into numbers that our trusty machine can understand. That's why Data Preprocessing is super important!
Feel free to revisit the previous chapters in this series to refresh your memory and grasp everything fully.
And guess what? Here's the complete code we've been rocking! 🌟 You can grab it all in one neat package from my GitHub page. Just hop over here: GitHub - PythonicCloudAI/ML_W_PYTHON/Data_Preprocessing.ipynb.
Happy coding! 📥
# **Step 1: Import the necessary libraries**
import pandas as pd
import scipy
import numpy as np
from sklearn.preprocessing import MinMaxScaler
import seaborn as sns
import matplotlib.pyplot as plt
# **Step 2: Data Importing**
df = pd.read_csv('SampleData.csv')
# **Step 3 : Seggregation of dataset into Matrix of Features & Dependent Variable Vector**
x_features = df.iloc[:, :-1].values
y_dependent = df.iloc[:, -1].values
print(x_features)
print(y_dependent)
# **Step 4 : Handling missing Data**
from sklearn.impute import SimpleImputer
imputer = SimpleImputer(missing_values=np.nan, strategy='mean')
imputer.fit(x_features[:,1:3])
x_features[:,1:3] = imputer.transform(x_features[:,1:3])
print (x_features)
# # **Step 5 : Encoding Categorical Data : One Hot Encoding**
from sklearn.compose import ColumnTransformer
from sklearn.preprocessing import OneHotEncoder
column_transformer = ColumnTransformer(transformers=[('encoder',OneHotEncoder(),[0])], remainder='passthrough')
x_features = np.array(column_transformer.fit_transform(x_features))
print(x_features)
# **Step 6 : Encoding Categorical Data : Label Encoding**
from sklearn.preprocessing import LabelEncoder
label_encoding = LabelEncoder()
y_dependent = label_encoding.fit_transform(y_dependent)
print(y_dependent)
And with that, we wrap up for today where we completed Label Encoding 😊 . It's been a blast exploring how we can make our data more friendly for machines to understand.
Stay tuned for more exciting adventures in the realm of machine learning with python ! Until next time, happy coding and keep exploring! ✨ That's it for today, folks!